随着LLM的地位完成了从语言模型到Agent 大脑的转变,LLM愈发需要进行长期持久性的上下文管理,这对原有的RAG和memory技术形成了新的挑战,本文将从该角度出发,阐述最近memory管理的最新研究进展

1. 现有 Memory 评估和架构
让我们先看看原来的学术界中众所周知的Memory评估和架构有何缺陷?
评估
大海捞针的不足
“大海捞针”测试是之前评估模型memory能力或者利用参考上下文能力进行回复的能力的最广泛使用的方法之一,其代表是诸如 LoCoMo、LongMemEval 等基准测试。这些测试的底层逻辑是将记忆降维成一种静态的文本检索能力。在这些设定下,模型被一次性喂入极长的上下文(可能包含数万字的对话历史或文档碎片),随后被要求回答特定的事实性问题。但这种测试的局限性在于,将根据现有的大量信息进行推理 简化 为从海量上文中抽取事实,在实际agent的应用中,模型不仅要能够找到已有的信息碎片,更要根据这些信息进行下一步的逻辑推演并决策未来的行动。更进一步的,模型是否能够意识到海量上下文隐含的多个限制条件,从而对未来的动作进行调整;而不仅仅是抽取信息。
记忆与行动评估的割裂
另一个问题是,即使目前已经有了大量的工具调用与环境交互并行动基准测试,模型需要根据上下文对未来动作进行调整,大部分测试仍然被局限于“单次会话/问题”(Single-session/Single-Query),例如 SWE-Bench、WebArena、Mind2Web、browsecomp 以及 xbench等等。通常,所有的历史交互步骤可以都被当作扁平的上下文直接塞入模型的提示词窗口中。因为任务的生命周期极短且因果链条单一,智能体根本不需要跨越多个时间维度去主动抽象、存储和提取信息 。系统短期的工作记忆(Working Memory)足以应付这些任务,导致外部长效记忆(Long-term Memory)系统在此类基准中并非关键性决定因素(就我个人的经验来说,找一个长上下文的模型就足以解决上述benchmark中的问题,这比构造精巧的memory系统往往更快,效果也更好)。
常见架构范式
经过最近几个月的发展(截至2026年3月初),为了平衡成本和精度,目前对于Memory管理已经形成一些常用的范式,也有新的范式不断提出,下面先对记忆管理进行分类[Memory in the Age of AI Agents],本文后续重点聚焦于 token粒度的记忆管理,并将详细阐述一些新兴的挑战者带来的变革。
词元级记忆(Token-level Memory
[将信息存储为持久且离散的单元,这些单元在模型参数之外是可访问且可检查的。这里的‘令牌(token)’是一个广义的表征概念:除了文本令牌外,它还包括视觉令牌、音频帧——即任何可以在模型参数之外进行写入、检索、重组和修订的离散元素。]
词元级记忆中的记忆单元都是显式的,因此比较便于修改和理解。尽管所有的token级别记忆都具有“以离散单元形式存储”的共同属性,但它们在这些单元的组织方式上存在显著差异。token级别记忆的结构化组织方式,对于决定智能体(agent)搜索、更新或对过往信息进行推理的效率起着核心作用。参考 【】的分类方法,可以将token级别记忆进行分类,包括:
扁平记忆 (1D) / Flat Memory (1D): 单元之间没有显式的拓扑结构。记忆以序列(sequences)或单元集合(bags of units)的形式累积(例如:片段、轨迹、数据块)。
平面记忆 (2D) / Planar Memory (2D): 在单一平面内进行有结构但单层级的组织:单元通过图(graph)、树(tree)、表格(table)等方式相互关联,不存在跨层级关系。其结构是显式的,但非分层的。
分层记忆 (3D) / Hierarchical Memory (3D): 跨越多个层级进行结构化组织,层与层之间存在链接,形成体状(volumetric)或层化(stratified)的存储。
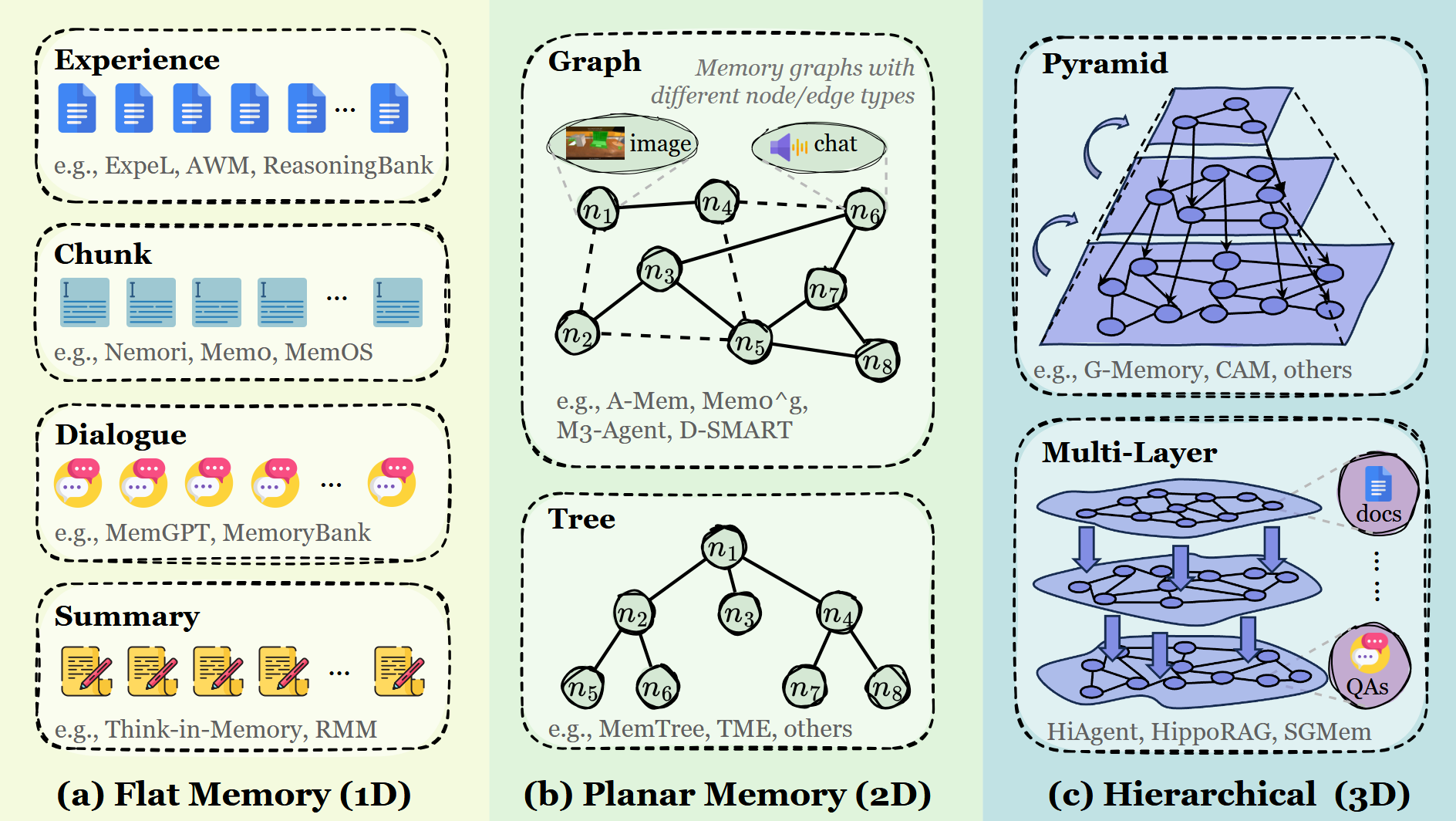 扁平记忆(1D)
扁平记忆(1D)
简要来说,扁平(1D)形式就是最常见的组织形式,不同储存单元之间的关系并没有直接进行储存。扁平存储的主要优势在于其简洁性与可扩展性: 存储空间可以以极低的成本进行增补或删减,而诸如相似度搜索(similarity search)之类的检索方法允许灵活访问,无需预设结构。这使得它们非常适合宽泛的回溯(broad recall)、情景积累(episodic accumulation)以及快速变化的交互历史记录。另外许多扁平记忆还支持对内容进行摘要,如 Letta(前身为 MemGPT)、Mem0 以及 MemoRAG 等高级外挂记忆系统,不再进行字面意义上的全量存储。它们在底层引入了启发式规则或经过专门训练的神经模块,对历史轨迹进行压缩、总结和提炼(Consolidating and distilling information)。
然而,缺乏显式的关联组织意味着其连贯性和相关性高度依赖于检索质量。随着记忆规模的增长,冗余和噪声会不断堆积,模型可能会检索出相关的单元,却无法理解它们之间的内在联系。这限制了组合推理(compositional reasoning)、长程规划(long-horizon planning)以及抽象概念的形成。因此,这种无拓扑结构的集合在实现广泛覆盖和轻量化更新方面表现卓越,但在需要结构化推断或稳定知识组织的任务中则显得捉襟见肘。
平面记忆(2D)
平面形式(2D)在1D基础上*在存储单元之间引入了显式的组织拓扑结构,但仅限于单一的结构层级。相比于1D,2D通过建立显式的关联机制,突破了单一存储池(storage pool)的限制,实现了从单纯的“存储”向“组织”的飞跃。平面记忆通过在节点间有效建立链接,使记忆能够利用“集体协同效应(collective synergies)”,从而编码更全面的上下文知识。 此外,它支持超越简单迭代的检索机制,包括结构化键值查询(key–value lookups)以及沿图边缘进行的关系遍历(relational traversal)。同时,也能够进行对一,这些能力使其在记忆的存储、组织和管理方面表现强劲。
然而,它也面临一个关键限制:由于缺乏分层存储机制,所有记忆必须被整合进一个单一的、庞大的模块中。 随着任务场景的复杂度与多样性不断增加,这种冗余且扁平化的设计在维持鲁棒性能方面显得日益乏力。更重要的是,其高昂的构建与搜索成本显著阻碍了它的实际部署。
分层记忆(3D)
分层(3D)在2D的基础上跨越多个层级组织信息,利用层间连接(inter-level connections)将记忆塑造为一个立体化(volumetric)的结构空间。这种层级结构支持不同抽象程度的表征——从原始观测数据(raw observations),到紧凑的事件摘要(event summaries),再到更高级别的类目模式(thematic patterns)。跨层连接进一步产生了一个立体的存储空间,系统不仅可以在单元之间进行横向导航,还可以在不同的抽象层级之间进行纵向穿梭。
分层记忆超越了简单的分层堆叠,旨在构建具备深层抽象能力和动态演进机制的复杂系统。此类研究通常采用多层图结构或受神经科学启发的机制,以构建更接近人类的立体存储空间。在这种空间中,信息更加丰富,存储单元之间的连接也更加清晰和显式。总的来说,分层记忆通过将存储节点置于层级(纵向)与关联(横向)维度的交汇点,分层存储允许不同的记忆相互作用,并形成多维度的协同效应(multi-dimensional synergies)。 这种设计有助于系统编码出更具全局性(holistic)且上下文语境更深厚的知识。该形式还支持强大的检索功能:它能够实现复杂的多路径查询,这些查询既可以在每一层内部的关系网络中横向穿梭,也可以在层与层之间的抽象级别上纵向移动。
然而,该结构的复杂性及其密集的信息组织方式,也给检索效率和整体效能带来了挑战。特别是如何确保所有存储的记忆始终保持语义上的意义,以及如何设计系统的最优三维布局(three-dimensional layout),仍是极其困难且关键的问题。
| 维度 | 存储类型 | 类比 | 核心特征 |
|---|---|---|---|
| 1D | 扁平 (Flat) | 散乱的纸条 | 只有先后顺序,找信息靠“翻”。 |
| 2D | 平面 (Planar) | 地图/导图 | 有了“路口”(连接),可以横向联想。 |
| 3D | 分层 (Hierarchical) | 图书馆/大脑 | 既有书架间的横向关联,又有“类别-书架-书籍-页码”的纵向抽象。 |
参数化内存(Parametric Memory)
与将信息存储为可见且可编辑的离散单元的“token级别记忆”不同,参数化记忆直接将信息存储在模型的参数中。根据记忆相对于核心模型参数的存储位置,可以将参数化存储分为两种主要形式:
内部参数化记忆 (Internal Parametric Memory): 记忆被编码在模型的原始参数(如权重、偏置)之中。这些方法通过直接调整基础模型(base model)来整合新的知识或行为。
外部参数化记忆 (External Parametric Memory): 记忆存储在额外或辅助的参数集中,例如适配器(Adapters)、LoRA 模块或轻量化代理模型。这些方法通过引入新参数来承载记忆,而无需修改原始模型的权重。
这种区分反映了一个核心的设计选择:是让记忆完全被基础模型“吸收”,还是以模块化的方式“挂载”在模型旁边。
隐式内存(Latent Memory)
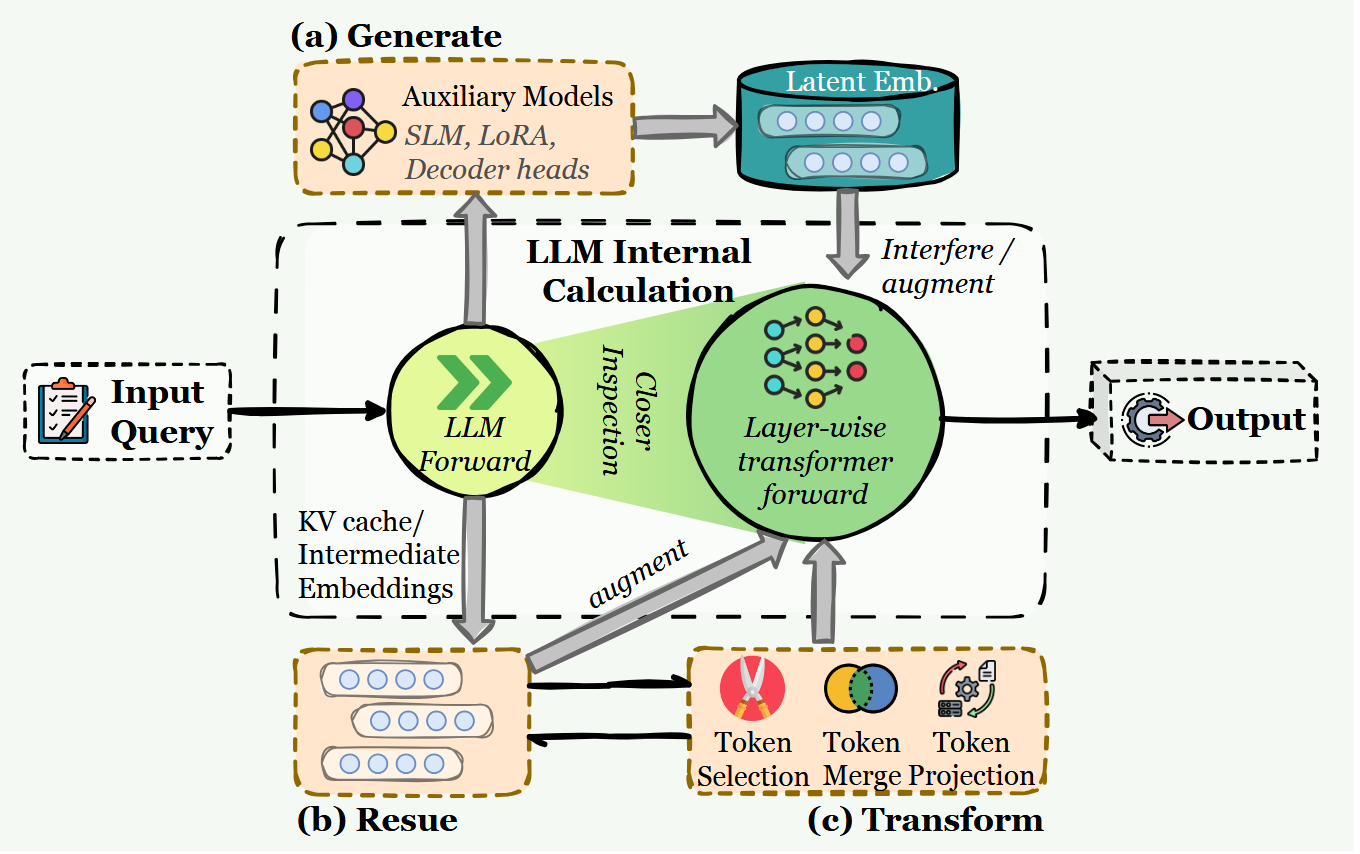 隐式存储是指隐含在模型内部表征(如 KV 缓存、激活值、隐藏状态、隐式嵌入)中的记忆,而不是以显式的、人类可读的令牌(tokens)或专门的参数集形式存储。(本质是一种以空间换时间的方法)根据隐式存储的来源(即隐式状态是如何形成并引入智能体的)可以进行分类:
隐式存储是指隐含在模型内部表征(如 KV 缓存、激活值、隐藏状态、隐式嵌入)中的记忆,而不是以显式的、人类可读的令牌(tokens)或专门的参数集形式存储。(本质是一种以空间换时间的方法)根据隐式存储的来源(即隐式状态是如何形成并引入智能体的)可以进行分类:
生成式 (Generate): 隐式存储由一个独立的模型或模块产生,然后作为可重复使用的内部表征提供给智能体。
复用式 (Reuse): 隐式存储直接从之前的计算中承袭而来,最典型的例子是 KV 缓存复用(在单轮内或跨轮对话中),以及传播隐藏状态的循环或有状态控制器。
转换式 (Transform): 将现有的隐式状态转换为新的表征(例如通过蒸馏、池化或压缩),使智能体能够保留核心要点,同时减少延迟和上下文占用。
对于这类方式,需要注意的是 生成过程本身可能会引入信息损失或偏差,且这些状态在多次读写循环中可能会发生偏移或误差累积。此外,训练一个专门用于生成隐式表征的模块会引入额外的计算开销、数据需求和工程复杂度。
新兴的Memory 评估与架构
EvoMemory
Memory Area
为了迫使智能体必须调用长效记忆机制,该数据集在构建数据时巧妙地利用了“依赖链”(Dependency Chains)的设计思维 。如果一个宏观任务可以被轻易地拆解为几个互不相干、可独立执行的子任务,那么记忆系统的价值就会被大幅度稀释。因此,“相互依赖”(Interdependent)成为了整个数据集构建的核心题眼。在后续的会话中,智能体接收到的任务指令往往是“欠指定”(Underspecified)的。这意味着,环境不会再次复述早期的约束条件,智能体必须主动检索并应用之前提炼的记忆作为当前决策的依据。下面是具体的数据类型举例:
| 评估领域 (Domain) | 总任务分布特征 | 相互依赖机制与记忆挑战维度 (Interdependency Mechanism & Challenges) |
|---|---|---|
| 捆绑网络购物 (Bundled Web Shopping) | 150 个宏观任务,平均每个任务包含 6 个子任务会话 | 前序购买的商品属性构成隐性的技术约束。例如,第三轮购买的电视壁挂支架必须与第一轮购买的电视机尺寸匹配,且绝对不能触发与第二轮购买的音箱型号相斥的规则。极度考验细粒度特征追踪与硬性逻辑互斥的记忆维持能力。 |
| 群体旅行规划 (Group Travel Planning) | 270 个群组规划任务,平均包含 9 个连续的旅行者加入会话 | 后续加入群组的旅行者的个人偏好严格依赖于先序旅行者的选择。例如,旅客 B 要求在第二天与旅客 A 预订同一家餐厅,且预算必须比 A 降低 10%。这要求智能体在记忆中进行动态状态追踪与跨实体关系推理,任何历史槽位数值的遗忘都会导致规划崩溃。 |
| 渐进式信息搜索 (Progressive Web Search) | 256 个极具挑战性的搜索任务,平均产生超 122k Tokens 的轨迹 | 后续的网络查询条件建立在前期搜索确认的特定实体之上,具有严格的因果时序。例如,查出某学者的毕业年份后,再以此为基础搜索该年份发表某特定论文的第二作者。考验模型在极长上下文噪音下的信息聚合与注意力防衰减能力。 |
| 序列化形式推理 (Sequential Formal Reasoning) | 40 个数学问题与 20 个物理问题,平均包含 12 个推导子任务 | 后续的数学或物理定理证明步骤必须精确无误地引用前期推导出的引理、边界条件或中间参数,否则严密的数学逻辑推导将直接断裂。这是对高密度抽象符号记忆准确复用与逻辑链延续能力的终极测试。 |
| 这些问题要求模型不仅记住每个点(人/物)各自的属性,跟需要能够理解并运用各个点之间关系(限制条件) |
揭示的问题: 表征错位(Representation Mismatch)。现在的长上下文基座模型(如 GPT-5.1-mini 或 Claude-Sonnet-4.5)在训练时,吸收的是具有极其强烈的时序性、逻辑连贯性和自我一致性的原生文本数据(Self-consistent, verbatim interaction history)。在处理单次超长会话时,它们能够利用底层的自注意力机制(Self-attention)和相对位置编码,熟练地在连贯的语境中追踪事件的演进。
然而,当系统强行接入 2D 或 3D 外部记忆引擎时,反馈给基座模型的信息格式发生了剧烈的突变。模型不再阅读连贯的“流水账”,而是接收到大量经过高度压缩、切片化(Segmented)或重新排序(Reordered)的碎片化信息片段 。对于习惯了原生语境的模型而言,这相当于正在阅读一部长篇小说时,突然被人抽走了书本,换成了几张写满断章取义结论的卡片笔记。由于失去了原始的历史语境、上下文的逻辑过渡以及时间戳的连续性,模型的上下文学习(In-context learning)能力无法与这种高度浓缩的输入格式实现完美的对齐。这种底层表征层面的摩擦,导致模型要么对这些记忆片段产生幻觉,要么无法准确理解其权重,进而做出了错误的推理。
训练错位(Training Mismatch)。现代的 LLM(Task Agent)与 外部记忆系统(External Memory / RAG)绝大多数情况下是由不同的团队分别独立开发、独立训练的,两者之间极度缺乏联合优化(Not jointly optimized)的训练过程 。
这种割裂导致了严重的问题,一方面,任务智能体并没有在强化学习阶段接受过关于“如何在部分信息缺失时向记忆库提出精准查询”的特定惩罚与奖励。因此,当面对需要检索的场景时,它往往会生成极其模糊、宽泛的检索指令,导致记忆库返回的内容噪音过大,或者完全遗漏了关键的隐性约束条件(如在旅行规划中未能指定查阅上一个人的航班到达时间)。另一方面,即使记忆库侥幸返回了绝对正确的信息,智能体在“融合”这些信息时也会发生致命的偏差。
相关的开源社区讨论(如 GitHub 上的开源项目 Risk Oracle 的开发实录)为这一“训练错位”提供了绝佳的现实佐证。在针对系统代码纠错的实际开发场景中,研究人员发现了一个令人沮丧的现象:“检索并不等于应用(Retrieval!= Application)” 。智能体即便在当前的上下文窗口中明确“看”到了记忆库返回的历史错误修正记录(Corrections),在执行下一步极具风险的代码提交或覆盖动作时,仍然可能因为未能深刻理解该记忆的严重性而重蹈覆辙。这是因为模型在训练时缺乏“基于外部召回记忆强制阻断当前高风险行动”的反馈回路。两套系统各自为战,导致了外挂记忆机制的整体失效。
另一个重要的问题是,任何使用摘要和总结的记忆系统,都难以做到不损失或者污染信息,而理想是记忆系统可以像状态机一样“更新系统关键参数”的逻辑,但现在的系统仍然远远达不到。
未来研判
第一,系统架构将从“外挂式机械检索”向“原生记忆融合模型”演进。单纯依赖在 API 应用层面外挂 RAG 或图数据库的做法,已经不可逆转地触碰到了能力的天花板。未来的发展强制要求基础模型(Foundation Models)在预训练(Pre-training)或基于人类/人工智能反馈的强化学习(RLHF/RLAIF)阶段,就将“向记忆库发起精准查询”以及“根据返回的碎片化记忆动态重构上下文”作为一种内生能力进行极其严苛的联合优化(Joint Optimization)。只有从底层抹除表征形式和训练目标上的错位,智能体才能像人类一样,自然、可信且毫不犹豫地运用跨越时空的长效记忆 。
第二,记忆基座的开发重心将从“语义相似度匹配”转向“显式的主动状态追踪(Active State Tracking)”。在 POMDP 的理论框架指引下,未来的记忆数据库不应该仅仅是一个被动的文档存储池,而应当升级为一个具备独立逻辑判断能力的主动状态更新引擎(Belief Update Engine)。它需要能够理解多级任务的因果依赖逻辑,主动维护、提取并覆写那些可能随时影响下游智能体决策的核心状态变量(例如群体规划中其他人的预算底线变化,或者长链条代码重构中的接口参数变更),而不是仅仅满足于“召回那些看起来语义相似但逻辑矛盾的废话” 。
第三,出于部署成本考量,将引入“多层级认知延迟架构(Hierarchical Latency Architecture)”。鉴于复杂的图结构等高级记忆机制目前会带来难以忍受的高昂执行延迟,未来的智能体操作系统在设计时必须融入分级的内存访问策略 。对于低风险、线性延续的日常步骤,优先利用底层模型长上下文窗口自带的高速并行处理能力进行快速启发式推进;而当系统内部探测到即将进行高风险动作(如修改核心系统代码、执行资金结算)或遭遇高度冲突的复杂逻辑推理时,再激活高延迟、高精度的结构化记忆深度回溯机制,从而在保证执行准确率的同时,将系统的综合算力开销和延迟时间控制在商业可接受的边界之内 。
[//]: # (ATM-bench 主要是多来源的内容作为记忆,拓宽了记忆的定义,记忆可以被广泛的认为是所有用户行为(比如用户的邮件等等),模型被要求从这些资料中提取出隐式的知识, https://gemini.google.com/app/fe0bfd843a6b5b5b)
Evo-Memory: Benchmarking LLM Agent Test-time Learning with Self-Evolving Memory
核心理念
这篇论文指出,现有的评估benchmark往往只把memory能力往往仅仅当作一个巨大的储存库中抽取某个关键细节,而并没有清晰的意识到,memory的真正价值在于从无限的上下文中抽象出具有广泛泛化能力的“策略”、“通则”与“规律,这也是论文极具创造力的提出“经验复用”,其核心在于“抽象推理策略”(Abstracts reasoning strategies)。在这种评估视角下,标志着 memory 的定义从 “特定事实锚定(Specific Facts Grounding)”到“启发式策略抽象(Heuristic Strategies Abstraction)”的范式转移,大型语言模型正从“静态知识检索操作员”演化为“具备终身学习能力的自我进化者”。
在上述背景下,对模型memory能力的评估,就转移到了输入为“流式序列化”场景下的评估,(可以想象为在真实世界的场景下,agent不断地运行,积累了近乎无限的上下文),并且在数据中人为的创建了一条”学习曲线“。例如,数据初期会提供许多基础技能和先验知识的相关上下文供模型学习,模型需要从中提取规律,并应用到后期的高阶符合任务中。这种场景下,评估的范式就变为了在动态的上下文中,不断更新其内部知识库,这种能力就是学术界与工业界成为 “测试时进化”(Test-time Evolution)的能力。
范式推广
这篇论文的更进一步的将memory系统融入了整个Agent运行的体系,提出了Agent运行的精密闭环 $(F, U, R, C)$:
检索(Search/Retrieval - $R$):当系统接收到新维度的挑战 $x_t$ 时,检索模块 $R$ 会激活。它并不是进行简单的全文匹配,而是在高维动态记忆图谱或向量空间 中寻找拓扑结构或语义表征最接近的历史节点。在底层工程实践中,这通常表现为使用稠密编码器(如本研究中采用的 BAAI/bge-base-en-v1.5)将文本映射为连续向量后的余弦相似度计算,或者是基于注意力机制对知识库进行的动态路由。
合成(Synthesis - $C$):检索回来的原始物料 $R_t$ 往往是冗杂且充满噪声的。真正的上下文构建器 $C$ 绝非简单的字符串强行拼接操作。它需要将检索到的历史数据进行信息降维、重组与结构化对齐,生成一个针对当前问题高度浓缩且“量身定制”的工作上下文(Working Context) $\tilde{C}_t$。这一数学操作在神经生物学层面完美模拟了人类大脑中“工作记忆”(Working Memory)对“长期记忆”(Long-term Memory)信息的提取、解码与显式化加载过程。
生成(Prediction/Generation - $F$):基础大型语言模型 $F$(如Gemini 2.5 Flash或Claude 3.7 Sonnet)扮演着中央处理器的角色。它根据浓缩提纯后的高质量提示 $\tilde{C}_t$ 进行纯粹的逻辑推理与决策计算 $\hat{y}_t$。这种分离机制确保了极其昂贵的LLM前向传播算力被精准地集中在核心演绎逻辑上,而非在动辄数十万Token的无意义历史长尾中盲目搜寻线索。
进化(Evolve - $U$):这是形成闭环的最关键枢纽,也是以往绝大多数系统(如早期的MemGPT或基础版RAG)严重缺失的一环。经历一旦转化为结果,智能体必须结合外部环境的客观反馈 $f_t$(例如:Python代码的编译报错日志、物理引擎中的碰撞反馈,或者是多步对话中的目标完成度),利用提取函数 $h$ 固化出极具信息熵的经验条目 $m_t$。随后,更新策略 $U$ 决定了这条新经验如何被整合进下一代内存 $M_{t+1}$ 中。这里的 $U$ 可以是极简的列表追加(Append),也可以是更高级的聚类摘要、置信度权重衰减,甚至是遇到严重冲突时的知识覆盖(Overwrite)与重写。
新架构-ReMem
这篇论文同时也提出了一种新框架,在该框架中,对memory的管理,变成了agent可以管控的一项可交互的行动。ReMem彻底破除了原来统治Agent设计模式的Reason + Act,在ReMem中模型可以在任意步骤执行memory管理。
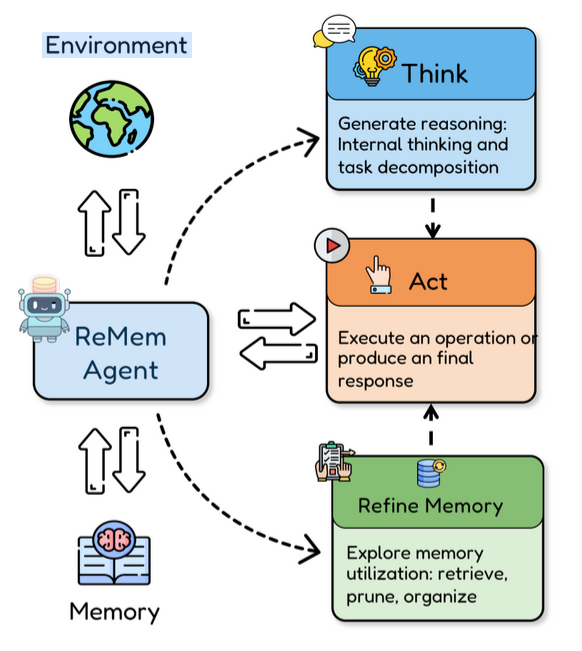 核心控制流:Think-Act-Refine 循环 在任意时间步 t,智能体接收到当前输入 xt、当前内存状态 Mt 以及历史推理轨迹后,可以在一个内部循环中自主选择执行以下三种核心操作之一 atn∈{Think, Act, Refine} :
核心控制流:Think-Act-Refine 循环 在任意时间步 t,智能体接收到当前输入 xt、当前内存状态 Mt 以及历史推理轨迹后,可以在一个内部循环中自主选择执行以下三种核心操作之一 atn∈{Think, Act, Refine} :
Think(思考): 智能体生成内部的逻辑推理轨迹,用于将复杂的当前任务进行拆解,或者规划下一步的方向 。
Refine(内存提炼与反思): 这是 ReMem 的独特创新。智能体会对当前的内存库进行元推理(Meta-reasoning)。它不仅可以主动发起检索(寻找类似困境的破局点),还可以主动对内存进行**修剪(Prune)**和重组,剔除掉被证明无效或干扰判断的噪声经验 。
Act(行动): 在物理环境或软件API中执行具体的指令,或者向用户输出最终答案。值得注意的是,在一个时间步内,智能体可以进行多次的 Think 和 Refine 循环,直到它确信可以采取具体行动时,才会输出 Act 指令来终止当前轮次的内部循环 。
其中Refine 包含三个核心动作:
主动检索利用(Exploiting useful experiences):当智能体的Think操作陷入死胡同,无法确定下一步行动方案时,它可以主动发起查询,去庞大的历史经验库中寻找类似困境的破局点,而不是盲目地在环境中随机尝试。
噪声果断修剪(Pruning noise):这是赋予内存生命力的关键。智能体会周期性地或基于特定触发条件审查当前的内存状态,将那些被后续实践证明是错误的、陈旧的、或者完全不相关的冗余经验进行物理删除或权重置零。这一算法机制高度拟合了人类大脑睡眠期间极为重要的“突触修剪”(Synaptic Pruning)与记忆巩固理论(这与Google DeepMind同时期关于AI长效记忆和“Dreams Agent”休眠计算理论的研究轨迹不谋而合)。
重组优化抽象(Reorganizing):智能体会对多个零散的、具体的经验条目进行归纳推理,将其重组和升华为更高维度的通则策略,以极高的压缩比存储到内存中。 这意味着,模型可以改写自己的状态,而不是只能在固定的架构里面不断重复固定的流程,赋予了模型自主进化的权力。
另外模型还做了多组实验,以下是几条重要结论:
- 在需要进行多轮行动的数据集上,ReMem效果很好,这说明 任务的视野跨度(Task Horizon)越长,动态自发建立的临时性局部记忆(Episodic Memory)就越发不可或缺。** 尤其是对于小模型来说,这种提升更加明显。
- 自我进化的 memory 对于内在逻辑类似的数据集效果较好,如果数据集中存在多种不同类型的问题(如GPQA),那么由于问题类型发散,模型很难学习到有效的经验用于提升效果。
- 课程学习在该模型下非常有效,从简单到难的输入问题,模型能够更好的学习。
- 如果数据集难度较高且各个问题的解题经验难以服用,最好把这些经验去掉,效果会更好。
- 作者认为ReMem在长期运行的agent模型上具有独特的价值,随着时间的积累,能带给用户独一无二的体验。